
Tag: Geospatial
-
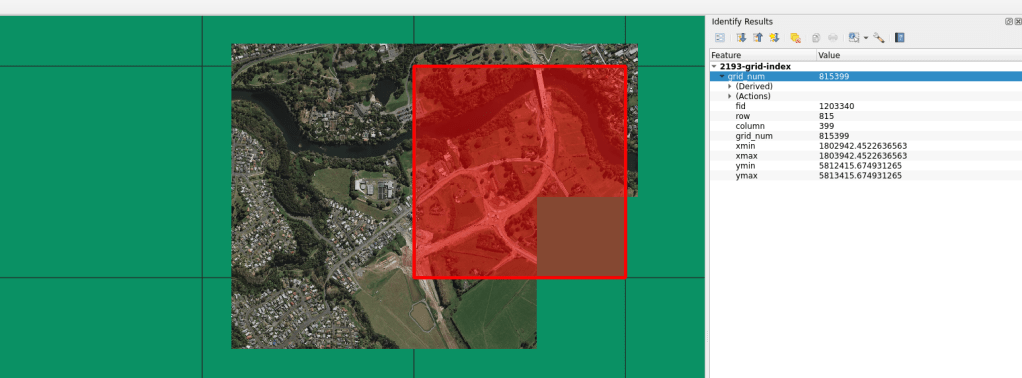
Projection Grid
There are times when I need a regular grid for an entire projection extent. Meaning, for the extent of an entire projection, I need to create a regular grid of uniform tiles across the projection. In past projects, these grids have been very helpful for data alignment and clipping data into uniform shapes and sizes.…
