XYCarto
Gallery
Blog
GitHub
Contact
Tag:
DEM
Geospatial
Basic GRASS GIS with BASH, plus GDAL
Geospatial
Basic GRASS GIS with BASH
cartography
,
Geospatial
Wellington Elevations: Interpolating the Bathymetry
cartography
,
Geospatial
Building the Wellington Model with 1m DEM and DSM
cartography
The Rejects
cartography
,
Geospatial
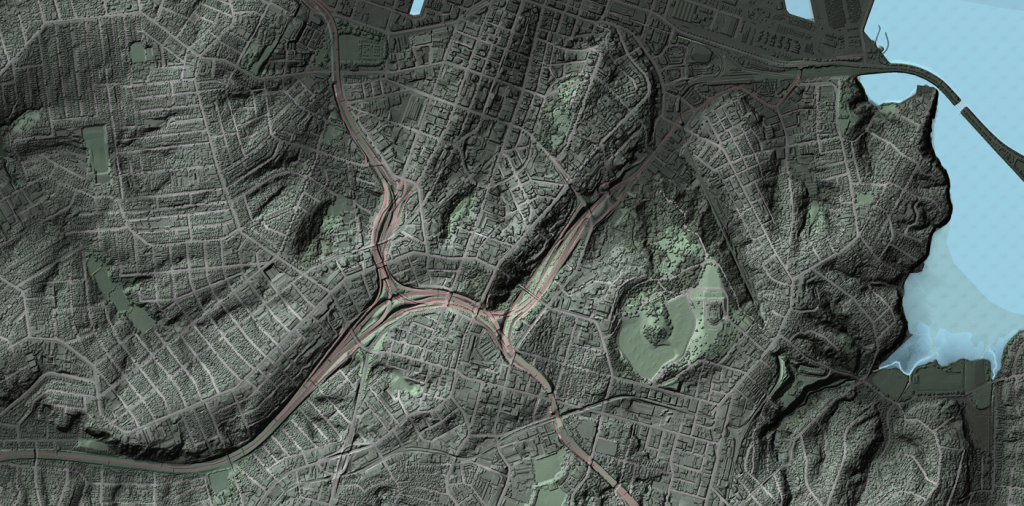
Processing and Visualizing Auckland 1m DEM/DSM Elevation Data
Subscribe
Subscribed
XYCarto
Sign me up
Already have a WordPress.com account?
Log in now.
XYCarto
Edit Site
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar